Database optimisation, analytics and burnout

Though this article has a lot of tech jargon, there is an underlying message that I hope to make accessible to all. It's not really important to understand the jargon, and where it is, I try to explain it.
For the past few months, I've been working on Pathogen, my data analytics pipeline.
I will reference Neptune and Monolith in this article. No other code from below remains, with the exception of Threshold, which resides inside Monolith.
The beginning
It was organised into a few rather incoherent scantily integrated parts:
- Neptune, the frontend, querying Elasticsearch to return results to the user
- The creatively-named "discord" script, a Discord bot which gathered messages it then forwarded to Logstash
- Threshold, which did the same for IRC, but was a much larger and older project with other data-analysis capabilities
- Crawler, a fully asynchronous (async) 4chan crawler and indexer, which ran a continuous crawl of 4chan and sent any new or updated posts to Logstash
- Research, a script which iterated over all the content in Elasticsearch and annotated it with sentiment and extracted keywords
Those pretty much summarise the self-made parts of the project, but in addition, these were used:
- Elasticsearch to store all the messages
- Logstash to relay messages to Elasticsearch, and throttling them so Elasticsearch could keep up in the case of a sudden surge
- Kibana to query Elasticsearch and present a friendly user interface where I can make fancy graphs, but notably, it was not possible for other users to access it without posing a serious security risk
The bricks start to fall
Neptune was doing well, and the queries to ES (Elasticsearch) seemed fast at first, I was impressed with how fast a Java-riddled behemoth could serve data to my end users! I had a personal distaste for Java, for seemingly no particular reason, and desired something faster, easier to use, and lighter on memory usage. Little did I know that ES had good reason to be slow, it did things I wanted!
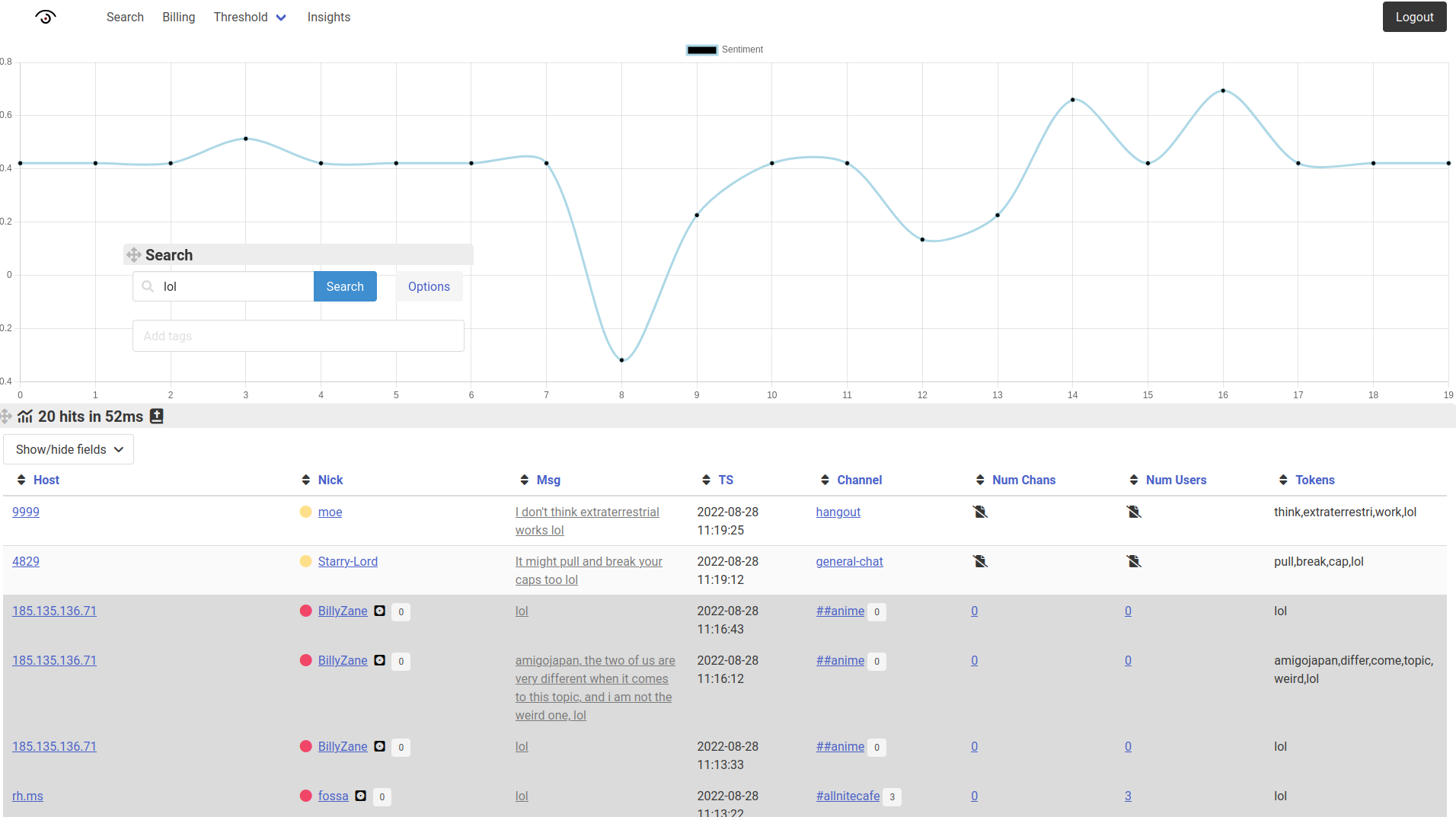
For kicks, I set the query size to 1000 and played with the settings, adding a latency counter to the user interface in the process. This let me profile which queries were fast, and which queries would block my application for some time, preventing other users from making queries for that duration.
I saw that small queries up to 25 results were extremely fast: 2ms. Turning up the size topped out at an abysmal 1600ms for 1000 results. Any more would have crashed my browser.
This observation ignited in me a deep desire to optimise the hell out of this project, a primal drive that would last for several months and completely reform the nature of the technology stack. Along the way, I learned more than I could ever have possibly hoped, and what was, in hindsight, a total loss of perspective, led to one of the most incredible redesigns of my project I've ever had.
Exploration
I was craving to see the text "1000 results in 25ms" on the interface.
After a brief exploration period of enterprise-heavy Elasticsearch alternatives that reminded me of once again working for a bigcorp, I settled on a search engine I've had my eye on for a while: Manticore Search. Initial tests showed that Manticore was channeling magical power from higher realms.
Or so it seemed, I've never in my life seen such a massive increase in performance:

It was consistently at least 10x faster than Elasticsearch! My search had concluded, or so I thought...
Manticore: the implementation
Obviously, I was keen to implement this as soon as possible. I learned that most of the code I'd written to interface with ES was totally reusable when switching to Manticore – while it primarily used SQL for queries, being a Sphinx fork, there was a REST API that accepted JSON, in a very similar format to ES. The syntax was documented, but a little hard to get to. Nevertheless, a few rather enjoyable hours later, Manticore was the primary driver in Neptune.
At the time, I only had Threshold and Discord ingestors, so modifying them was elementary, but raised a rather more important issue: I can't just keep adding random scripts together whenever I need something new indexed.
Clearly, I needed to combine what I had in some way, but the frameworks were so fundamentally different, I was not sure if this was possible. Discord used native Python async, while Threshold ran on Twisted. A few Google searches revealed that one person, more than 5 years ago, thought it might have been possible, and provided untested snippets of code, which in practice already began to make the project a lot more complicated than it needed to be. What I needed was to take a step back and see the bigger picture again.
The redesign
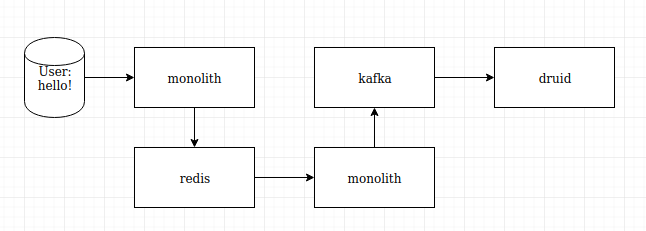
I've always loved diagrams and graphs, and reach for a Draw.io grain on my Sandstorm instance whenever more needs to be done than I can remember at once. I expected it to look more complicated, though.
I came up with a solution, but it wasn't as easy as I hoped. I often said to myself I'd eventually learn proper async, after fiddling around with Twisted's callbacks and handler chains in Pluto. Well, that time was now.
I began learning asyncio (Python's async) by reimplementing the 4chan crawler, which I developed in Twisted with Treq. I ported it to use aiohttp, and messed around with making it more efficient for a few weeks. Eventually, it got so fast that my computer couldn't keep up. I then throttled it so that it operated at a reasonable pace. There's no urgency to get the latest 4chan content, and I surely don't want to be blacklisted. I expected more rate limits from their side to be honest, but even several thousand requests per second didn't hit any kind of throttling.
This was a good start, and I now had a good working model of what I consider to be proper async in Python. The next logical step for me was to take a project I had that was already async – the Discord ingest handler, and implement it into the crawler.
The conception of Monolith
I felt the itch to create a new project and pick a cool-sounding name, and I settled on Monolith; conveying that I'm going to combine a bunch of things into one.
Combining two async frameworks proved more difficult than learning async in the first place. It wasn't that interesting though, so let's just say that I eventually got it to work. I had a single program to simultaneously connect to 4chan and crawl threads (the 4chan kind of threads, with offensive images and inflammatory text, not the ones we will cover later), while accepting Discord messages, storing the output of both into Manticore.

The fall of Research
Previously, I had a script to re-index documents in ES after they were ingested, adding information such as sentiment and keywords. This was no longer plausible with Manticore, and I could not figure out a way to make it work properly.
Needless to say, this became an enormous learning opportunity. I decided that Research was superfluous; there was no need to only process messages as fast as we could, I wanted the results of the processing to be available immediately. If there was too many messages to process, Research is only delaying the inevitable: having a massive backlog we never work through.
After a few choice words, I settled on attempting to put the processing logic directly into Monolith. After all, it was the last thing to see the messages before they get written to the database.
I worked tirelessly to get the processing functions to not block the tasks which crawled 4chan and checked Discord messages, but was ultimately unsuccessful. The lesson I took away from this was: async isn't magic.
Concurrency in Monolith
What I was trying to do was never going to work, since async is valuable only if you're waiting for something outside your immediate control, be it IO or network. Here, we were hammering the CPU and running NLP on the messages. It blocked the main thread and no more async tasks could execute until it was done.
I decided the solution was threads. Not just any threads though, async-compatible threads. I created some code to check the amount of cores the machine had, and spawned that many threads. We would be dividing up the messages equally, and then processing them in threads concurrently. The Discord and 4chan logic would still be happily running in the main async thread uninterrupted.

As it turned out, it was quite hard to get the output of many threads, ensure it was all available when we wanted to use it, and join the results back together, as if we had just done it in one thread.
This was initially only implemented for 4chan indexing, since it created so many messages, I could not ever process them in one thread, and having it block until that was done was unacceptable to me, since Discord messages would be delayed until it was complete, possibly skewing timestamps.
The next step was to implement this for Discord, but I realised I had not even given a thought to Threshold, the IRC indexer. I needed a way to link these together in such a way, that the multithreaded processer gets access to all of these messages together, in large but reasonable batches, to make the most of the cores I had.
Queueing

My first issue was that Threshold was now nowhere to be seen. It was only compatible with Logstash, and we didn't have that anymore, so my first task was to put Threshold into Monolith, and create a separate container for it to run in.
I did not really feel up to converting it to async so we could integrate it more closely with Monolith, since it was an old and highly specialised project, which accounted for and dealt with a large number of IRC protocol oddities I'd experienced over the years, and was heavily involved with Twisted's IRCClient implementation. I knew firsthand how much handholding Twisted gives you, and I still experienced issues, so I didn't even consider writing my own IRC library with async support.
Once that was in, I adjusted it to output messages to a Redis queue. I then implemented an ingestor service in Monolith to take messages from it and run it through the processing pool.
Some brief profiling showed that this was severely underusing the processing capabilities I had available to me, since Threshold's batches rarely contained more than 2 messages at once, while 4chan's batches sometimes exceeded 10,000 messages.

I adjusted the Discord and 4chan indexers to point to the same Redis queue, so all of the messages would be first written to Redis, then read back in configurable batches. These batches now would contain messages from all three sources.
A brief interlude of cache optimisation
Once everything was flowing smoothly, I repeated my benchmarking tests, and saw that the latency was a lot lower, but some complex queries now take even longer than ES did! I decided to do what I should have done in the first instance: I implemented some Redis caching for query results.
This was incredibly easy to implement and made the repeated query time drop to around 2-20ms, even for complex queries. It was only fetching data from RAM, after all. I used the EXPIRE Redis command to automatically purge the cache entries after a minute or so to save some resources and keep the data as live as possible. The great thing was that even a cache timeout of a second, would limit database query times to one query per second, per user, and significantly throttle any attempt to overwhelm the system through denial of service.
The re-redesign
What? Again? You just redesigned everything.
One of the gotchas with switching to Manticore was that it did not have the extensive graphing and data insight capabilities of Kibana, and while a beta Kibana port was in progress, trying it revealed that it was not ready for the kind of things I wanted to do.
Neptune, the web interface had a simple graph I could use to check sentiment, but Kibana was a sophisticated tool, with crossfilter support, that my web development skills just couldn't compete with at the time. I started looking for other options for data visualisation.
This search revealed Apache Superset, a data visualisation tool similar to Kibana. Attempting to get it to work with Manticore, however, was a whole other issue. There was an existing SphinxQL connector, and given that Manticore was forked from SphinxQL, I decided to give it a try. You can probably guess how that went. Searches further afield revealed that even if I was using Sphinx, something it would have worked with, my searching abilities would be limited to a subset (pun intended) of what was previously possible with Kibana:
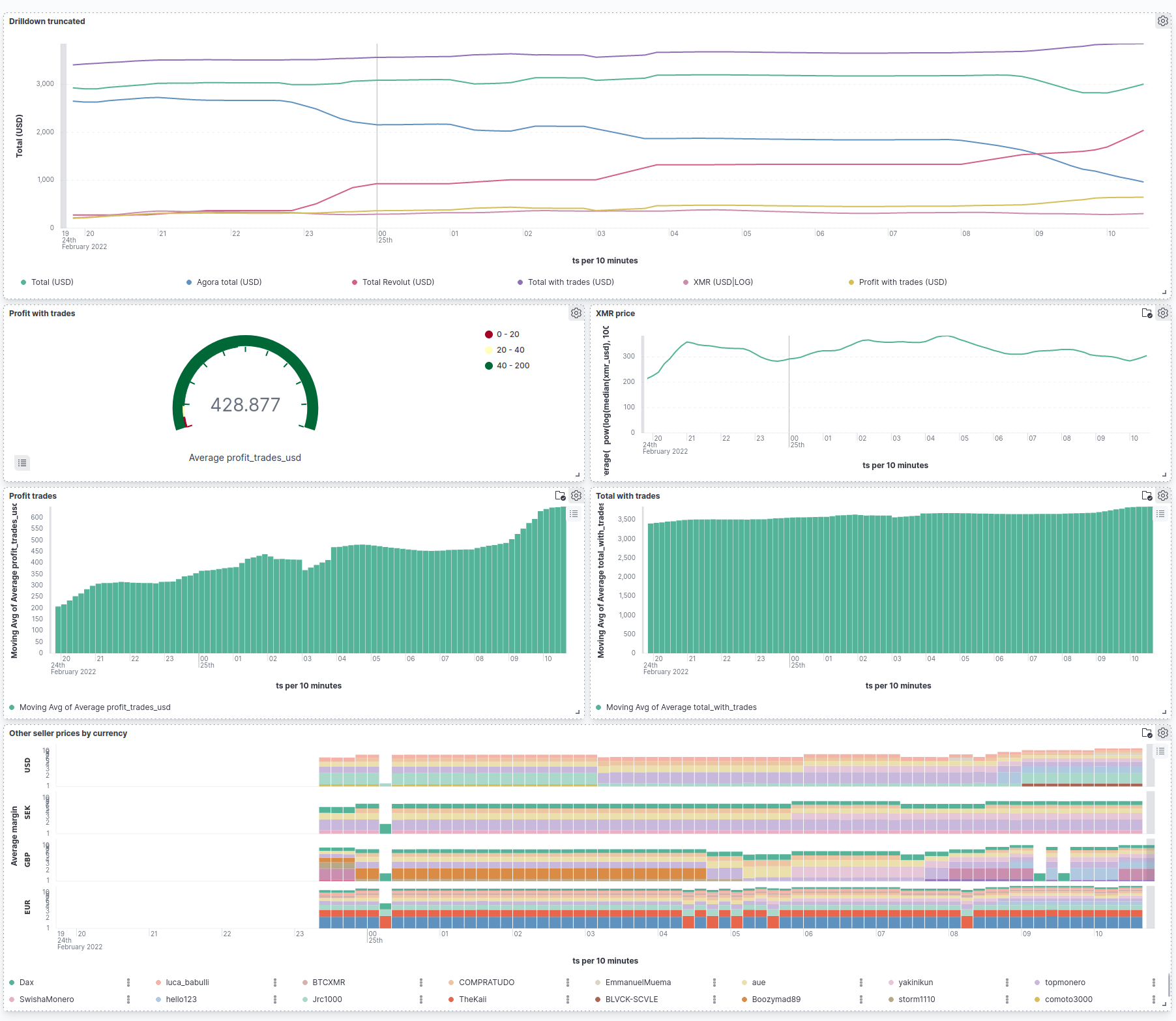
It was clear that if I wanted deeper data insights, I would have to change database engine again. Yes, again.
Enter Druid
Once again, after a long and difficult search, I had settled on Apache Druid. It was, after all, developed by the same people who made the data visualisation tool I wanted to use. This similarity reminded me of Elasticsearch and Kibana.
So once again, I found myself rewriting the database searching code for Neptune, only this time, I decided that, if this ends up not being the engine for me, I don't ever want to go through this pain again. With this, I developed a generic storage backend driver which would use whichever search engine you wanted to, and left the Elasticsearch and Manticore code there, only minimally restructuring it, without rewriting it to work properly with the backend.
Implementing Druid was difficult, but it was also easy. Dealing with the Elasticsearch syntax, I was used to a certain level of complexity, and perhaps expected it from all database products I used.
After some more choice words were uttered, I dedicated an evening to actually reading the documentation for Druid, and discovered that this one was not like the others. It was more optimised for Top N queries, rather than returning data from the database verbatim. I noted this point for later, as I misused many API calls in order to implement things Druid should never have been doing.
Delving so deeply into the documentation made me understand that Druid's syntax was even simpler than Elasticsearch or Manticore! It was just different, and in the moment, that made it complicated. Once I understood roughly what Druid was, it was much easier to use its API to do everything Elasticsearch or Manticore did before.

Looking at the Superset interface, I realised I could never hope to implement something nearly as fancy as this, so I started looking again at data visualisation products that worked with Druid, my intention being binning off Neptune for the analytics part, and instead using something like Superset, but for customers. I was spoilt for choice. Despite using a product ill-fitted for my workload, I could use Superset, MetaSearch, Turnilo. I adjusted my goals to focus on the ingestion pipeline, and hoped I could use these products to showcase my data, without getting into the nitty-gritty of reinventing the wheel and creating graphs from my data, when clearly there is something already out there that can do it.
The cracks start to show
After trying a few data visualisation tools with Druid, I was disappointed. Not because they were bad, they were among the best I'd ever used. No, I was disappointed with the amount of resources it seemed to take in order to complete elementary tasks. Fetching multiple columns of data seemed to run into resource exhaustion issues. It took me several weeks of debugging and one very useful conversation on the Druid Slack channel before I even begun to resolve these issues.

Druid was a beast, and I didn't know how to tame it. You needed a calculator to figure out how much memory it needed based on several other settings I still don't quite understand. It contained a plethora of services, which by default ran in many Docker containers.
Nevertheless, I persisted, I created my own Dockerised build of Druid which ran in only one container, and I used the development quickstart resource definitions, which did not seem to apply normally, despite the documentation stating otherwise. I'm sure my journey would have been less painful if I'd been open to the possibility of there being flaws in the product I'm using, rather than simply assuming whatever is going wrong is my fault.
Many headaches later, Druid was working. Kind of. Query times eventually slowed, but it stopped running out of resources.

Except it didn't. Several months later, I logged on to see the process had crashed completely. Cue another few weeks of debugging, and I realised I was not setting up the data pipeline in the proper way, and that Druid needs enough RAM to process one batch at once, and doesn't buffer it to the disk, so I decreased the maximum permitted size until it stopped crashing.
Going home
Several months passed, and I had not worked on anything to do with Pathogen in the meantime. My server was constantly overloaded, and I was begrudgingly eyeing up the next VPS tier on Vultr. During this time I worked on some other projects, but couldn't touch Pathogen infrastructure, I had wanted to do n-grams with MongoDB, but was unsure whether the VPS I had could handle it.
I started work on a cryptocurrency trading bot, Fisk, which I'm sure I'll get to writing about. The experience taught me a lot about Django internals, and eventually I became keen to implement these changes in Neptune as well. I'd started thinking about setting up an Elasticsearch/Kibana instance for Fisk, so I could see a profit graph over time, only to remember that Druid was currently hogging all the resources.
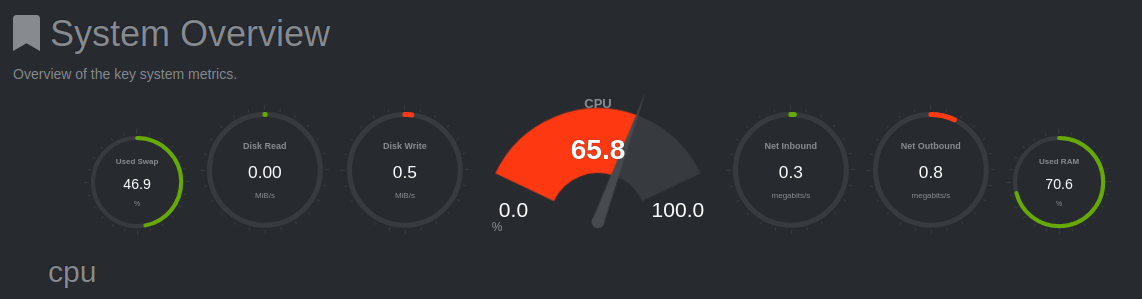
It was time to go back to what worked. I needed an ES instance to use with Fisk, and I craved a glance at the insightful and easy to use dashboards of Kibana.
I begun the now-not-so-tiresome work of implementing ES with Monolith, and finishing the storage backend implementation for ES in Neptune. I'm pleased that my search for optimisation resulted in very significant performance improvements, and taught me about a broad range of technologies. I'm less pleased about losing my footing and going optimisation-crazy, and eventually getting burned out.
To summarise

My key takeaway here is:
There's always another millisecond to shave off the execution time, but how long are you going to spend doing it?